1. 해시(Hash)의 개념
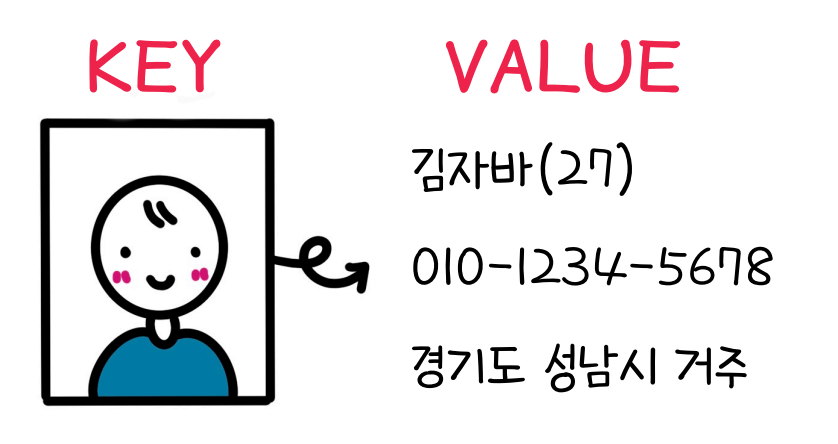
Value : 우리가 저장하고자 하는 데이터 값들
Key : Value를 관리하기 위해 1:1로 매칭 (고유한 값, 중복 없음)
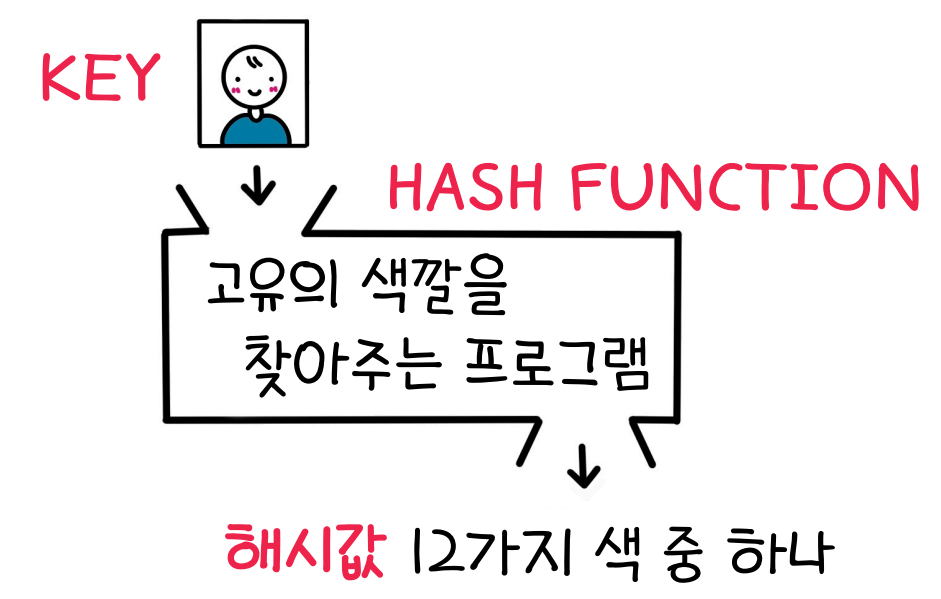
Key
Hash Function : Key를 넣어주면 고유한 Hash value를 출력하여 인덱스화 한다.
Hash Value

Hash Table : 인덱스화된 Hash Value를 저장하는 자료구조
(Key, Value)쌍을 저장하여 순서가 없다.
Buckets : 데이터가 저장되는 공간
해싱 (Hashing)
데이터를 빠르게 저장하고 가져오는 기법 중 하나
키에 특정 연산(Hash Function)을 적용하여 테이블(Hash Table)의 주소를 계산
Hash Function에 의한 데이터 접근은 키를 이용하여 해시값으로 직접 매핑되므로 시간복잡도는 O(1)이 된다.
※ 좋은 해시 함수의 조건
키 값을 고르게 분포 시킴 (해시 충돌을 최소화하기 위함)
빠른 계산
충돌 최소화
2. 해시 충돌 (Hash Collision)
키 값이 다른데, 해시 함수의 결과 값이 동일한 경우

비둘기 집 원리 / Birthday Problem 두 가지로 이러한 해시 충돌이 일어나게 되는 이유를 설명
임의의 사람 N명이 모였을 때 그 중에 생이 같은 두 명이 존재할 확률이
23명만 모여도 50.7% / 50명인 경우 97% 라고 한다.
이러한 해시 충돌을 피하기 위한 방법 2가지
Chaining
해시 값이 중복되면 Linked List로 노드를 연결해서 가르키도록 한다.
중복된 해시값의 경우 값 탐색을 위해 Linked List를 하나씩 타고 들어가서 탐색함으로
중복 노드가 늘어날 수록 O(n)의 시간 복잡도가 필요하다.
따라서 중복된 해시 값을 Linked List로 연결하는 것이 전통적인 방식이나,
현재는 이를 트리 구로 연결하는 방식도 사용되고 있다.

Open Addressing
충독 발생 시 다른 버킷에 데이터를 저장
다른 버킷을 어떻게 찾아서 저장하느냐에 따라 방법이 나눠지게 된다.
- 선형탐색 : 해시 충돌 시 n 칸을 건너 뛴 다음 버킷에 저장
- 계산이 단순 / 검색 시간이 많이 소요 / 데이터들이 특정 위치에만 밀집(Clustering)
- 제곱 탐색 : 해시 충돌 시 n2 칸을 건너 뛴 버킷에 데이터를 저장
- 이중 해시 : 해시 값이 중복 되면 다른 해시 함수를 한번 더 적용한다.
Hashfunction1(): 최초의 해시 값을 구함
Hashfunction2(): 충돌 발생 시 이동 폭을 구함
최초 해시 값이 같더라도 이동 폭이 다르기 때문에 Clustering 문제를 해결 할 수 있다.
3. 해시(Hash) 구현 - JAVA
Key-Value 쌍의 노드로 구현
해시충돌이 발생했을 경우 Linked List를 이용한 Separate Chaining으로 해결
package hashtable;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class MyLinkedHashTable<K, V> implements IHashTable<K, V> {
private static final DEFAULT_BUCKET_SIZE = 1024;
private List<Node>[] buckets; // hashTable -> chaining 리스트에 노드가 하나씩 들어가는 모양
private int size;
private int bucketSize;
public MyLinkedHashTable() { // 생성자
this.buckets = new List[DEFAULT_BUCKET_SIZE]; // 2의 10제곱
this.bucketSize = DEFAULT_BUCKET_SIZE;
this.size = 0;
for(int i = 0; i < bucketSize; i++) { // bucketsize 만큼 bucket을 돌면서 초기화
this.buckets[i] = new LinkedList<>();
}
}
public MyLinkedHashTable(int bucketSize) { //사용자가 버킷사이즈를 선택할 수 있는 생성자
this.buckets = new List[bucketSize];
this.bucketSize = bucketSize;
this.size = 0;
for(int i = 0; i < bucketSize; i++) {
this.buckets[i] = new LinkedList<>();
}
}
@Override
public void put(K key, V value) { // 새로운 노드를 해쉬 테이블에 집어 넣는 동작
int idx = this.hash(key); // hash function으로 인덱스 정보를 가져온다
List<Node> bucket = this.buckets[idx]; // 가져온 인덱스 해당되는 node를 불러온다
for (Node node : bucket) { // 전체 node를 순환하면서 key값이 같은 노드가 있으면 value를 새것으로 바꿔라
if (node.key.equals(key)) {
node.data = value;
return;
}
}
Node node = new Node(key, value);
bucket.add(node);
this.size++;
}
@Override
public V get(K key) { // 해쉬 테이블에서 key값에 해당하는 value를 가져오는 동작
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for (Node node : bucket) {
if (node.key.equals(key)) {
return node.data;
}
}
return null;
}
@Override
public boolean delete(K key) { // 해쉬 테이블의 데이터를 삭제하는 동작
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for (Iterator<Node> iter = bucket.iterator(); iter.hasNext(); ) {
Node node = iter.next();
if (node.key.equals(key)) {
iter.remove();
this.size--;
return true;
}
}
return false;
}
@Override
public boolean contains(K key) { // 해당 키에 해쉬 태이블에 데이터가 있는지 알려주는 동작
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for (Node node : bucket) {
if (node.key.equals(key)) {
return true;
}
}
return false;
}
@Override
public int size() {
return this.size;
}
private int hash(K key) { //hash function 구현
int hash = 0;
for (Character ch : key.toString().toCharArray()) {
hash += (int) ch;
}
return hash % this.bucketSize;
}
private class Node { // key-value node 생성
K key;
V data;
Node(K key, V data) {
this.key = key;
this.data = data;
}
}
}4. 해시(Hash) 구현 - Python
class Node:
def __init__(self, key, val):
self.key = key
self.val = val
class HashTable:
def __init__(self, bucket_size=1024):
self.buckets = [[]] * bucket_size
self.bucket_size = bucket_size
self._size = 0
def put(self, key, val):
idx = hash(key) % self.bucket_size
for elem in self.buckets[idx]:
if elem.key == key:
elem.val = val
return
node = Node(key, val)
self.buckets[idx].append(node)
self._size += 1
def get(self, key):
idx = hash(key) % self.bucket_size
for elem in self.buckets[idx]:
if elem.key == key:
return elem.val
return None
def contains(self, key):
idx = hash(key) % self.bucket_size
for elem in self.buckets[idx]:
if elem.key == key:
return True
return False
def delete(self, key):
idx = hash(key) % self.bucket_size
for idx, elem in enumerate(self.buckets[idx]):
if elem.key == key:
self.buckets[idx].remove(elem)
self._size -= 1
def size(self):
return self._size
if __name__ == "__main__":
table = HashTable()
print('table.put("s1", "v1")')
table.put("s1", "v1")
print('table.put("s2", "v2")')
table.put("s2", "v2")
print('table.put("s3", "v3")')
table.put("s3", "v3")
print(f"table.size(): {table.size()}")
print(f"table.get('s1'): {table.get('s1')}")
print(f"table.get('s2'): {table.get('s2')}")
print(f"table.get('s3'): {table.get('s3')}")
print("table.put('s2', 'v4')")
table.put("s2", "v4")
print(f"table.get('s2'): {table.get('s2')}")
print("table.delete('s2')")
print(table.delete("s2"))
print(f"table.size(): {table.size()}")
print(f"table.get('s1'): {table.get('s1')}")
print(f"table.get('s2'): {table.get('s2')}")
print(f"table.get('s3'): {table.get('s3')}")
'Basic Computer Science > Data Structure' 카테고리의 다른 글
| 13. 정렬(Sort) - 이진탐색(Binary Search) (0) | 2023.08.03 |
|---|---|
| 12. 해시 - 알고리즘 문제 (0) | 2023.08.02 |
| 10. 큐 - 알고리즘 문제 (0) | 2023.07.20 |
| 9. 큐(Queue) - 원형 큐(Circular Queue) (0) | 2023.07.20 |
| 8. 큐(Queue) - 선형 큐(Linked Queue) (0) | 2023.07.19 |
댓글